
Motivation
As increasing numbers of developers are discovering, Meteor is an incredibly powerful, feature-rich platform with which to create web apps. By obviating many of the traditional frustrations involved in rolling out a production app, like user authentication or synchronisation of data on client and server, Meteor makes it remarkably easy to progress from idea to prototype to fully-functional product in no time at all. However, the developer can become dazzled by such power, and there’s the danger that he or she can end up producing complex, multi-page applications without fully understanding one of the most fundamental components of the platform - the Pub/Sub framework. This is certainly an accurate description of my personal history with Meteor, and a situation I have recently put right, as I describe below.
Meteor.publish
The first remark I should make is that the canonical demonstration of Meteor’s low-level publish API not only exists, but it’s almost the first thing to appear in the official documentation. I can only assume that this is part of the problem - the counts-by-room example is relatively subtle and benefits from some understanding of DDP (the protocol developed by Meteor specifically for client-server communication) - which will probably leave many readers skipping over it on their first visit in their enthusiasm to get to the shiny stuff below. Which, it turns out, is a mistake, at least judging by the number of recent questions on SO which can be resolved with a good understanding of this topic.
Two Publication Patterns within a single Method
Anybody who has some familiarity with Meteor will be aware of the first of the available publication patterns, in which the publish function uses the familiar collection API to return a collection cursor. Those with knowledge of DDP will also be aware that the cursor object itself cannot actually be communicated via this protocol, so returning a cursor is really a way of describing the documents (current and future) which the app designer wants to make available on the client. Meteor’s internals then take care of the actual transmission of these objects via DDP, as well as continuing to observe the cursor for changes and sending the ready message after initial transmission, which is used by the onReady callback and ready methods on the client side, and further utilised in iron-router’s wait method and waitOn hooks.
Here’s the basic setup to which I’ll be referring, which involves a test collection being populated with a random integer in the range [0, 1000) every ten seconds. There’s also an example of the familiar cursor-based pub-sub pattern:
TestData = new Meteor.Collection('testdata');
if (Meteor.isServer) {
Meteor.publish('cursorPub', function(filter) {
return TestData.find(filter || {});
});
Meteor.startup(function () {
Meteor.setInterval(function() {
TestData.insert({number: Math.floor(Math.random() * 1000)});
}, 10000);
});
}
if (Meteor.isClient) {
Session.set('filter', {});
Deps.autorun(function(c) {
mySub = Meteor.subscribe('cursorPub', Session.get('filter'));
});
}Note that the subscription on the client side is contained within a Deps.autorun block and depends on a reactive Session variable. This means that we can change the subscription filter simply by changing the value of the session variable, and Meteor is clever enough to manage the resubscription (including doing nothing if the filter hasn’t actually changed).
We can use the Websockets filter in the Network inspector within Chrome Dev Tools to see exactly how this pub/sub example translates into DDP messages sent and received by the client:
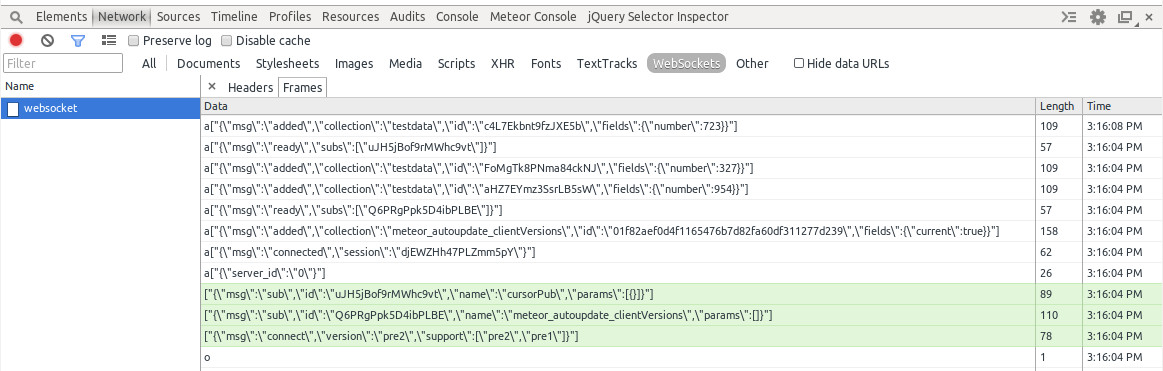
Reading from the bottom up, and ignoring messages relating to the meteor_autoupdate_clientVersions subscription, which is a meteor internal, we can see the following:
- A
connectmessage sent by the client to the server. - A
subscribemessage for thecursorPubpublication, coming from the client, with an attached subscription id. - The
connectedmessage returned by the server. - Two
addedmessages returned with acollectionfield oftestdataso that the client knows where to store these documents, and the (in this case rather limited) document contents. - A
readymessage sent by the server indicating that initial data on this subscription has all been sent - note that thesubsfield has the same id as thesubscribemessage which was sent by the client in step (2). - A further
addedmessage as thesetIntervalblock on the server runs again and adds a new document to the collection. Meteor is automatically observing the cursor which was returned by theMeteor.publishblock and sending any changes to subscribing clients. Note that the timestamp on this message is several seconds after the others, confirming that this was a document added after the connection had been made and the initial data synchronised.
Distributed Data Protocol
The second way to use the Pub/Sub model is really just an API to exactly this DDP flow from the server side, relating to a specific connection and subscription request. What this means is that the named publication function will be run once for each incoming subscription on that name, but rather than returning a cursor and leaving it for Meteor to generate the required DDP messages, it allows us to send customised DDP messages to suit the requirements of the application. Here’s an example which does exactly the same as the one above:
Meteor.publish('ddpPub', function(filter) {
var self = this;
var subHandle = TestData.find(filter || {}).observeChanges({
added: function (id, fields) {
self.added("testdata", id, fields);
},
changed: function(id, fields) {
self.changed("testdata", id, fields);
},
removed: function (id) {
self.removed("testdata", id);
}
});
self.ready();
self.onStop(function () {
subHandle.stop();
});
});So what exactly are we doing here?
- Storing a reference to the publish function’s context in
self, as we’ll need to use it inside the functions contained withinobserveChanges, where the value ofthiswill be different. - Setting up an observer to monitor the
TestDatacollection (appropriately filtered). In this simple example, we are simply passing any changes to the returned document set on the server (i.e. when documents areadded,changedorremoved) to the subscribing client verbatim, by instructing the publish function to send an appropriate DDP message with exactly the same details down to the client. This is what theself.added,self.changedandself.removedcalls are doing. - Note that these functions will run immediately in a synchronous manner for that specific subscriber, so all the existing documents will fire the
addedhook before any further processing is done. - Thus, by the time we reach
self.ready()we can be confident that all the existing documents have already been sent withself.addedcalls, and it’s safe to tell the client that their subscription is ready to use. It’s very important that we make this call at some stage, otherwise anything that hooks into the subscription’sreadymethod will never be fired. - Finally, we have to make sure we
stopthe observer when the subscription is closed (at which point theonStopcallback is fired). If we don’t do this then the server will continue to observe the document set until it is restarted, even with no subscriber to send changes to, and server resource utilisation will increase inexorably as clients connect and reconnect. This would not be a good outcome!
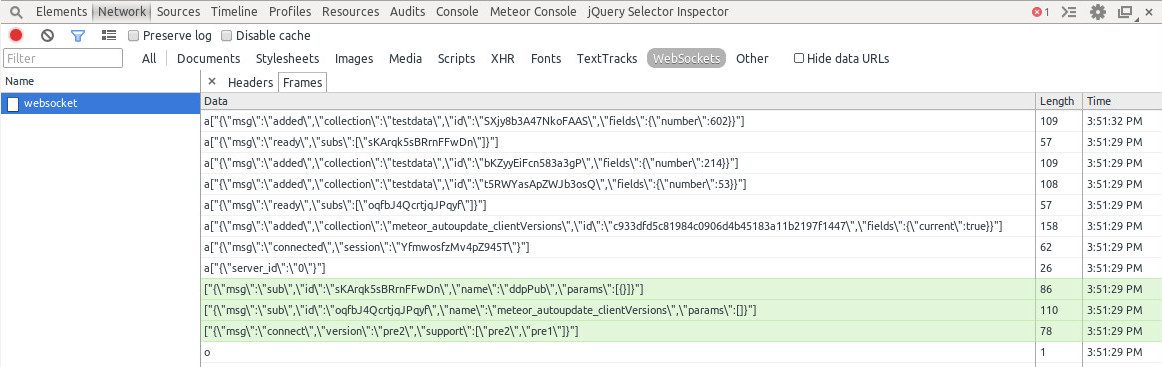
When we inspect the result in Chrome Dev Tools, the result is uncannily similar:
Something Rather More Useful
At this stage, it would be reasonable to ask what the point of all this was, since we’ve just recreated exactly the same series of messages using significantly more code. But the fact that we now have a way of intermediating the conversation between client and server databases gives us a huge amount of power. This is utilised very cleverly in the counts-by-room example provided within the Meteor docs, but I’m going to take a slightly different tack.
Existing Documents versus New Additions
One question which is regularly asked on Stack Overflow and elsewhere relates to how the client can be sure its local collection has been fully synchronised before attempting to work with it. I would argue that the majority of cases can be resolved with sensible use of the ready() method, which is reactive and triggered by the DDP ready message we’ve seen above. However, whilst I am no expert on websockets and stand to be corrected, I am certain that there are cases in which the order in which messages are sent from the server isn’t necessarily the same as the order in which they’re received by the client, at least if there is a degree of latency involved. What this means is that the ready message would arrive before one or more documents. Perhaps this is no problem, as Meteor’s built-in reactivity will re-render everything as soon as the missing documents arrive and the client will barely even notice. But what if even that outcome is unacceptable?
Pattern 1: A Document Counter
One way of confirming that the original document set had arrived intact would be to send the number of documents added before the ready call as an additional document itself. This would best be done using another collection to avoid the need to filter it out of the data set that you’re actually interested in communicating.
CollectionCount = new Meteor.Collection('collectioncount'); // NOTE THAT THIS ONLY NEEDS TO BE DECLARED ON THE CLIENT
Meteor.publish('ddpPub', function(filter) { // WHILST THIS IS OBVIOUSLY ON THE SERVER
var self = this,
ready = false,
count = 0;
var subHandle = TestData.find(filter || {}).observeChanges({
added: function (id, fields) {
if (!ready)
count ++;
self.added("testdata", id, fields);
},
changed: function(id, fields) {
self.changed("testdata", id, fields);
},
removed: function (id) {
self.removed("testdata", id);
}
});
self.added("collectioncount", Random.id(), {Collection: "testdata", Count: count});
self.ready();
ready = true;
self.onStop(function () {
subHandle.stop();
});
});This publish function will also populate the CollectionCount collection (which only needs to be constructed on the client) with an object that contains the number of documents in the existing set. You can then delay mission critical logic on the client until TestData.find().count() is equal to CollectionCount.findOne({Collection: "testdata"}).Count. Note that the actual logic will need to be slightly more involved to account for the period in which CollectionCount.findOne({Collection: "testdata"}) returns nothing as the publish function hasn’t yet sent the corresponding message.
Pattern 2: An Additional Field
A similar scenario is one in which we don’t need to know the exact number of documents in the collection when we subscribe, but we do need to know which they are. This can be solved as follows:
Meteor.publish('ddpPub', function(filter) {
var self = this,
ready = false;
var subHandle = TestData.find(filter || {}).observeChanges({
added: function (id, fields) {
if (!ready)
fields.existing = true;
self.added("testdata", id, fields);
},
changed: function(id, fields) {
self.changed("testdata", id, fields);
},
removed: function (id) {
self.removed("testdata", id);
}
});
self.ready();
ready = true;
self.onStop(function () {
subHandle.stop();
});
});Now if we query the collection on the client immediately after we’ve received the ready message, we will notice that TestData.find().count is equal to TestData.find({existing: true}).count(). However, once additional documents are added on the client side, this will cease to be the case as these will no longer have the existing property, allowing us to identify that these are genuinely newly-added documents from a global perspective.
The two examples above could be combined to solve a problem in which data was being rapidly generated and the client needed to be sure that, not only did it have the right number of documents, but those were exactly the documents in the existing set. Alternatively, in some use cases, we might not want to send the existing documents over the wire at all, in which case we would simply not execute the self.added call if !ready evaluated to true.
Conclusion
Hopefully, this has shed some light on the power and flexibility of the low-level Publications API, which I believe is frequently ignored by Meteor enthusiasts who may have grown too accustomed to the convenience of the higher-level cursor-based API. I’m sure there are hundreds of interesting and more elaborate use-cases, involving selective updates, periodic removals, record extension with myriad extra data and so on, and I look forward to seeing them.
A Note on Subscriptions
Finally, as I pointed out earlier, I have chosen to put my subscription inside a Deps.autorun block on the client side, to allow automatic resubscription when the filter is amended. This provides other benefits from a reactivity perspective:
- If you have a Template helper which has a dependency on the readiness of a subscription, this allows you to resubscribe and maintain reactivity. What this means is that
mySub.ready()in the example above will always reactively supply the state of the current subscription, even though the actual subscription object has been stopped and replaced by a new one. This is very convenient! - In contrast, if you don’t put your subscription in a
Deps.autorunblock like this, your reactivity can break when you resubscribe. This means that if you were usingmySub.ready()in a helper function (or another reactive context) and then resubscribe withmySub = Meteor.subscribe('testdata', newFilter);your helper will not rerun. For this reason I would always recommend putting your subscriptions inDeps.autorunblocks and having them update by changing the value of Session variables, or another reactive data source. - By default, a subscription that runs within a
Deps.autorunwill not actually resubscribe if there is no effective change in the subscription request, even if theautorunblock is rerun. I can’t imagine a scenario in which this behaviour would be undesirable, but if that’s ever the case you could force a resubscription by just includingmySub.stop()before theMeteor.subscribeline in theautorunblock.